
Практика внедрения DR в крупном ритейле
Недавно писали о классификации Tier и отказоустойчивости ЦОДов. Выяснили, что уровень доступности самого распространенного Tier III – 99,982%, а максимальное время простоя – 1.6 часа в год.
Но если авария всё же произошла, а на счету минуты, используют Disaster Recovery, или аварийное восстановление.
ИТ-архитектор CORTEL, Сергей Шевалье, поделился своим опытом внедрения DR в крупном ритейле.
С чего всё началось?
Компания – крупнейший производитель одежды и обуви с оборотом 10,8 млрд в год. Управляет несколькими онлайн платформами и владеет 353 магазинами в 141 городе.
Причиной внедрения DR послужили несколько серьезных инцидентов в работе ИТ-систем, которые, по счастливой случайности, не привели к ощутимым последствиям:
– сбой в системе автоматического ввода резерва ЦОДа;
– инцидент со сбоем в системе хранения данных
– поделился Сергей.
По данным Gartner, современный бизнес зависит на 75%-95% от собственных приложений и ИТ-инфраструктуры, на которой они “живут”:
– 43% поддержка бизнес-процессов;
– 33% стратегическое управление информацией;
– 13 % создание продуктов и услуг;
– 11% сокращение расходов и реструктуризация.
Цели DR – обеспечение непрерывности работы и минимизация негативных последствий от сбоев ИТ систем
– продолжил Сергей.
Шаг 1: Определили параметры доступности
Прежде чем приступать к созданию плана аварийного восстановления, нужно было понять, какой ущерб будет нанесён в случае аварии. Для этого определяем:
RTO, Recovery Time Objective – время, в течение которого система может оставаться недоступной.
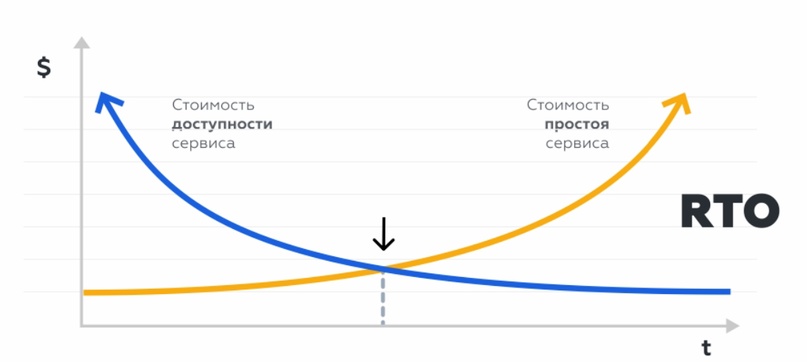
RPO, Recovery Point Objective – максимальный период, за который могут быть потеряны данные.
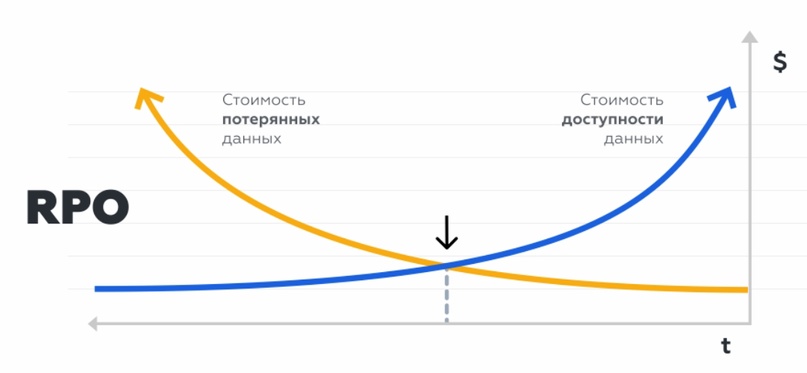
Для начала смоделировали аварии с разными параметрами RTO и RPO и посчитали последствия влияния на функциональность бизнеса. Выяснили, что для некоторых критичных сервисов потребуются минимальный RTO – простой не может длиться более нескольких минут. RPO составил 0, то есть, недопустима потеря ни одной операции, так как компания теряла репутацию, прибыль и критично важные данные.
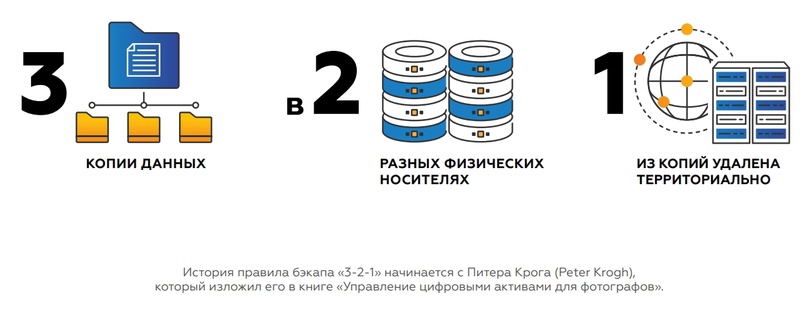
Для менее требовательных сервисов решили обеспечить катастрофоустойчивость «классическим» способом – резервным копированием по схеме 3-2-1.
Шаг 2: Составили план аварийного восстановления – Disaster Recovery Plan
Для критичных сервисов решили:
- Построить сеть географически распределённых ЦОДов, связанных L2 каналами.
- Настроить асинхронную репликацию баз данных.
- Разработать автоматическую схему переключения рабочей нагрузки в случае недоступности данных в одном из ЦОДов на другие.
План пришлось доработать, так как время, в течение которого система могла оставаться недоступной, приближалось к 0, однако период, за который теряли данные, было недопустимо велик – примерно 10 секунд.
Шаг 3: Танцуем с бубном и делаем RPO=0
Доработали 1С на торговых точках так, чтобы последние операции хранились локально.
Благодаря этому, при потере транзакций во время переключения между ЦОДами, данные восстанавливались из локальной базы конкретного магазина.
Вторым плюсом стала возможность сохранять ограниченную функциональность магазина при отключении интернета или потери связи с ЦОД. Все операции сохраняются локально, а при появлении связи добавляются в основную БД.
Шаг 4: Как понять, что всё работает?
Чтобы увидеть, насколько эффективен DRP и довести действия персонала до автоматизма, проводились регулярные тестовые проверки и учения с переключениями на резервный ЦОД.
Появилась уверенность, что практически в 100% случаев мы решим любую проблему, которая может привести к простою торговых точек или бизнеса. В случае сбоя всегда можно переключиться на резервный ЦОД, а потом разбираться в причинах инцидента
– заключил Сергей Шевалье.
Как использовать сторонние мощности для резервного ЦОДа и сократить для себя управленческие и финансовые риски – писали здесь.
О том, как корпорации – Google Amazon YouTube – работают над непрерывностью работы сервисов – тут.
Что такое “Двухскоростное ИТ” и как совместить требования к безопасности с регулярными обновлениями – тут.