
Техподдержка в ITSM: как решить любой тикет за 15 минут

Меня зовут Алексей Ревенко, я – руководитель Центра мониторинга и технической поддержки CORTEL.
Ежегодно мы опрашиваем клиентов, довольны ли они качеством услуг. И в 100% случаев заказчики отмечают и хвалят скорость, качество работы и вовлечённость саппорта. Несколько цитат:
С CORTEL можно связаться в любое время. Если сравнивать с другими крупными поставщиками услуг, там такой возможности нет
– Андрей Сидорович, IT-директор «Тактикум»
С CORTEL появилась 100% уверенность в непрерывной работе ИТ-систем, скорости реагирования и техподдержке, которая всегда на связи
– ИТ-директор крупнейшей электроэнергетической компании
Мы получили всю необходимую поддержку от специалистов CORTEL – оперативно и в нужном объеме, минуя формальности
– ИТ директор “СИБИНТЕРФАРМ”
В этой статье расскажу всё о внутренней кухне нашей техподдержки и разберу путь тикета от звонка клиента до решения его проблемы на нескольких примерах. Спойлер: часто этот путь начинается ещё до обращения заказчика.
Главное о саппорте: инструменты, принципы и показатели
Работа нашей техподдержки базируется на соответствии ITIL – мировому стандарту для IT Service Management.
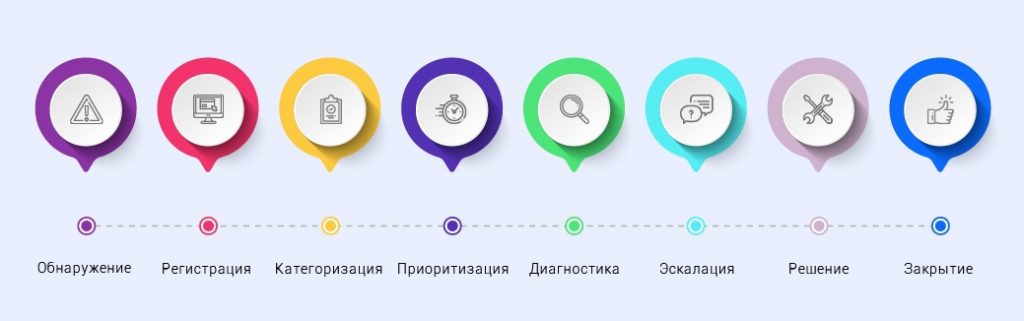
Стандарт подразумевает поэтапный конвейер, который позволяет не потерять ни одно обращение и не затянуть работу, а ответить максимально быстро.
Работу саппорта мы оцениваем по двум ключевым показателям:
- SLA по срокам взятия в работу. Время получения первого ответа от техподдержки – 90 секунд. И неважно, по какому каналу клиент обратился — с помощью электронной почты, по телефону или в личном чате в соцсетях. Время получения первого ответа от техподдержки – 90 секунд. И неважно, по какому каналу.
- SLA по срокам решения запросов клиента. По основным категориям:
– информационные запросы;
– запросы на изменения конфигурации системы;
– запросы на текущее обслуживание;
– аварийные ситуации.
При обработке 95% тикетов мы укладываемся в параметры SLA. Если это не происходит, мы анализируем каждый такой кейс: смотрим, что нам помешало решить проблему в срок и как нам уложиться в отведённое время в следующий раз.

Запросы бывают разными, и наша ключевая особенность в том, что мы оперативно отвечаем клиентам всегда, даже на самые нестандартные, возможно, даже не касающиеся нашей работы.
То есть, клиенты не всегда обращаются по вопросам относительно предоставляемых услуг. Мы консультируем, помогаем везде, где можем – как на теории, так и на практике. Например, даём необходимую литературу, ссылки, методы исправления ошибки – вплоть до встречи по видеоконференцсвязи.
Чтобы оперативно отреагировать, локализовать и начать решать проблему, у нас есть целый “боевой набор”:
Системы мониторинга (в частности, Zabbix) – регистрируют отклонения информационных систем от заданных параметров.
Система ведения заявок и инцидентов – здесь фиксируем все обращения, историю их решения и меры устранения.
База знаний — в ней храним информацию по обращениям: документацию по стандартным решениям, информацию о конфигурации услуг для каждого клиента, справочные материалы.
ИС по размещению оборудования, линиям связи, линиям электропитания и дополнительное ПО для диагностики.
Почему у нас сразу три линии техподдержки
Большинство запросов клиентов мы решаем уже на первой линии. Но если поступает нестандартное или критически важное обращение, то мы передаём его на вторую или даже сразу на третью линию.
Каждая линия техподдержки выполняет четко ограниченные задачи и выполняет свою роль в едином процессе.
Первая линия
Здесь операторы работают посменно в режиме 24/7 – выявляют, классифицируют и регистрируют первичные запросы от заказчиков по различным каналам. Каждому обращению присваивается номер и создается тикет в системе Help Desk.
Также в задачи первой линии входят оповещение клиента о возможном инциденте на основе данных мониторинга и информирование о статусе работы над обращением.

Вторая линия
Здесь работают старшие операторы, также в режиме 24/7. Они уже непосредственно решают проблему клиента — самостоятельно по инструкциям либо перенаправляют обращение на третью линию.
Если ситуация стандартная, и инструкции у нас уже есть – используем их. Если нет, то оперативно привлекаем инженеров, экспертов и после каждой такой заявки добавляем информацию в базу знаний.
Соответственно, в следующий раз, когда клиент обратится с подобной проблемой, мы сможем решить её самостоятельно уже здесь.
Третья линия
Здесь решаются самые сложные и нетиповые задачи. В устранении проблем участвуют ведущий инженер и или эксперт профильного направления.

При необходимости собираем рабочую группу по устранению инцидента. Делаем это в любое время дня и ночи, даже в праздники, совместными усилиями, вплоть до создания видеочата с клиентом, работаем, пока не решим его проблему.
Как это выглядит на практике
Ситуация 1
Сначала от системы мониторинга, а затем от пользователей поступили сообщения – портал самообслуживания и сайт клиента недоступны в сетях некоторых операторов.
При этом в других сетях всё работало штатно – и мы начали искать причины. Было ясно, что они будут нестандартными, поэтому привлекли экспертов по информационной безопасности. После проверок выяснили, что дело не во внешнем вмешательстве.
Наконец, по косвенным признакам обнаружили корень проблемы – сбой у регистрационного оператора домена. Оказалось, что клиент забыл вовремя продлить домен. У некоторых операторов DNS-записи уже обновились, что и вызвало проблемы с доступностью сайта.
Я лично обратился к регистрационному оператору, и сервис был восстановлен.
Ситуация 2
Системы мониторинга сообщили о критическом сбое на одной из площадок, где мы размещаем оборудование – пропало электропитание.
Время, как и всегда, играло против нас. Мы привлекли сотрудников ЦОД для выяснения ситуации. Оказалось, что проходили плановые работы, о которых нас не предупредили. Всё бы ничего – наше оборудование было зарезервировано, так что отсутствие электропитания на одном луче не было критичным для инфраструктуры и сервисов.
Но у наших клиентов в этом ЦОД было размещено оборудование на colocation, и некоторые из них, рискуя, установили оборудование только с одним блоком питания – под личную ответственность. Их системы оказались частично без электроэнергии.
Сотрудник нашего производственно-технического отдела отправился в ЦОД. Ему предстояло быстро прибыть на место, получить доступ и переключить питание оборудования на второй луч.
Когда клиент заметил проблему и обратился к саппорт, наш сотрудник уже находился в ЦОДе – от сбоя до восстановления прошло менее часа.
Так, мы не только начали решать проблему до того, как клиент обратился к нам, но и смогли минимизировать ущерб для его бизнеса, не дожидаясь дополнительных согласований. Кроме того, после мы установили автоматическое включение резерва, чтобы в будущем исключить подобные инциденты.
Аварии на инфраструктуре – это всегда про принятие быстрых решений. В таких ситуациях важно понимать, где можно отступить от регламента, чтобы ускорить решение проблемы. Эксперты третьей линии владеют этим искусством: они не ждали, пока ЦОД закончит работы, а пошли и сделали всё возможное.
Ситуация 3
Клиент сообщил о сбое в работе сайта и сервисов. Системы мониторинга зафиксировали длительную и массовую DDoS-атаку со стороны ИТ-армии Украины.
Чтобы обеспечить непрерывность работы сервисов, клиент сотрудничал, помимо нас, с двумя поставщиками услуг защиты от DDoS. В момент атаки эти операторы не смогли выделить специалистов и быстро устранить инцидент.
Атака была сложной, “ковровой” – то есть, запросы маскировались под реальных пользователей на разных уровнях – от L3 – сетевого до L7 – приложений. Когда мы по просьбе заказчика закрыли доступ по геолокации, его клиенты начали сообщать о недоступности сайта. Подход пришлось кардинально поменять, на протяжении пяти часов мы вручную отбивались от атаки в режиме реального времени.
Все были в равных условиях, и вы – единственная компания, которая смогла организовать коммуникацию и совместными усилиями решить эту проблему. Это был нестандартный опыт, и вы очень нас впечатлили
– ИТ-директор заказчика
Подробнее о решении нестандартных ситуаций и взаимодействии нашего саппорта с клиентами читайте в разделе с кейсами.
Почему мы больше, чем просто саппорт
Мы готовы делиться и обмениваться экспертным опытом, что всегда подчеркивают наши клиенты. Консультируем, даём необходимую литературу, ссылки, методы исправления ошибки – вплоть до встречи по видеоконференцсвязи. Часто даже выезжаем в офисы заказчиков на несколько дней и вручную помогаем с установкой и настройкой сервисов. Даже если по договору он должен выполнять это самостоятельно.
В других компаниях нам предлагали общую поддержку через чат или почту, а индивидуальных консультаций у инженера не было. Работа с CORTEL строится по другому. Когда в 4 часа ночи у нас вышел из строя сервер, инженеры CORTEL в течении 30 мин устранили инцидент, обеспечив прямое взаимодействие инженерных команд. Удобно работать, когда за поддержкой можно обратиться в любое время и оперативно ее получить. Если сотрудники CORTEL не могут дать ответ сразу, они всегда сориентируют по срокам
— Чингис Юндунов, ИТ-директор ООО “СИБИНТЕРФАРМ”
Мы с удовольствием делимся экспертными знаниями не только с заказчиками, но и со всеми интересующимися. Подписывайтесь на наш уютный Telegram-канал о лучших практиках, кейсах и ИТ-экономике.