
SRE. Как обеспечить непрерывность работы веб-сервисов?
За последние 5 недель наши заказчики стали значительно чаще задаваться одним и тем же вопросом – как обеспечить непрерывную работу своих онлайн-сервисов? Это, в том числе, связано с тем, что в 2022 году резко увеличилось количество кибератак.
Поэтому мы написали развёрнутый материал для владельцев бизнеса, завязанного на работе веб-сервисов.
Индустрия ещё в прошлом десятилетии определила лучшие практики и сформировала необходимый подход к обеспечению непрерывной работы сайтов и приложений, которыми сегодня пользуются миллиарды клиентов.
Как потерять 100 млн. рублей за несколько часов?
С начала года эксперты фиксируют резкий рост количества и продолжительности кибератак. Это касается каждого владельца нагруженных веб-приложений и сайтов.
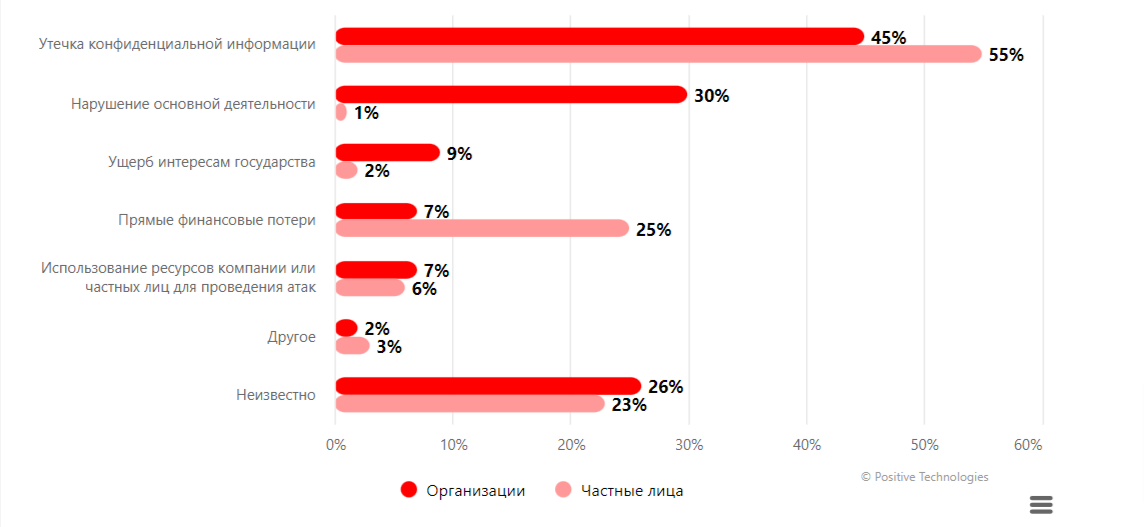
По результатам исследования Positive Technologies:
- количество атак увеличилось на 14,8% по сравнению с IV кварталом 2021 года.
- увеличилась доля массовых атак: теперь их количество составляет 33% от общего числа.
- Чаще всего в результате атак организации сталкиваются с утечкой конфиденциальной информации (45%) и нарушением основной деятельности (30%).
- В атаках на частных лиц чаще всего были скомпрометированы конфиденциальные данные (55%), также пользователи могли понести финансовые потери (25%).
Понятно, что простой приложения или сайта бьёт по выручке. Но часто мы даже не представляем, насколько сильно. Бизнес осознаёт, к чему приводит, например, остановка инфраструктуры маркетплейса в день распродажи.
Пример из практики:
Заказчик — крупный дистрибьютор продуктов питания в Казахстане (более 200 магазинов и 6000 сотрудников).
В ноябре 2020 года в ЦОДе, где была размещена ИТ-инфраструктура, произошла авария. 1С не доступна, работа точек по всей стране парализована. За 8 часов простоя организация потеряла более 100 млн. рублей.
После инцидента компания стала клиентом Cortel с запросом: сделать так, чтобы подобного не повторилось.
Для этого Cortel разбила сервера и базы данных на кластеры, затем настроила резервное копирование на каждой площадке
Что в итоге?
– 1С работает непрерывно под SLA 99,955
– Менее 4 часов простоя бизнес-критичных приложений в год, что соответствует требованиям бизнеса.
Как посчитать потери?
Период от остановки сервиса до его полного восстановления называют “простой” и у него есть стоимость, которая складывается из:
- потери дохода компании за период простоя;
- стоимости восстановления веб-сервиса после сбоя;
- размера потерь, связанных с падением производительности сотрудников;
- упущенной прибыли от потери лояльности клиентской базы.
Пример:
Если IT-инфраструктура Amazon остановится на минуту, потери сервиса составят порядка 66 240 долларов.
Стоимость простоя рассчитывается индивидуально и формируется из целей, возможностей и требований компании.
Представьте ситуацию: ваш бизнес остановился из-за простоя критичного веб-приложения. Сколько это будет стоить в случае остановки на 8 часов? А 48? Можете ли вы получить точные данные относительно каждого источника потерь?
Какой подход придумали в Google, и почему это в корне изменило подход к ИТ-инфраструктуре?
В 2003 году Google, уже будучи одной из крупнейших веб-компаний на планете, находилась на передовой нового типа пользовательского опыта, который предполагал минимальное время простоя и задержки.
Как ей это удалось? В компании изменили подход к работе с непрерывностью веб-сервисов.
Раньше разработчики и операционные службы представляли собой две команды с различными целями:
- Задача команды разработки – оперативно создавать конкурентоспособные обновления.
- Миссия операционных служб – сохранить стабильность приложения.
Они напрямую противоречат друг другу и создают конфликт интересов: чем больше обновлений, тем выше угроза нарушения непрерывной работы.
Так в 2003 году, под руководством Бена Трейнора Слосса, в Google возникла первая команда SRE (Site Reliability Engineering), которая напрямую занималась проектированием надёжности сайтов.
Ключевая задача SRE — поддерживать в работоспособном состоянии веб-системы, от которых зависит выручка и чистая прибыль.
Благодаря выстроенным процессам SRE, компания видит уязвимости и вовремя их ликвидирует, непрерывно укрепляя надежность системы.
SRE-инженеры обеспечивают стабильную и предсказуемую работу приложений/сайтов и т.д, обнаруживая проблемы до того, как о них сообщит клиент. Они объединяют команды разработки и операционные службы – и выстраивают единый, слаженный процесс.
Руководитель отдела по SRE в Google Эндрю Уидоусон описывает свою команду так:
«Мы — как самый быстрый в мире экипаж механиков. Мы на лету меняем шины гоночного автомобиля, мчащегося со скоростью 160 километров в час».
Как SRE распространился за пределы Google
Вслед за Google SRE стали внедрять крупные мировые компании:
– В Facebook команду SRE создали к 2010 году.
– Netflix собрал «основную команду SRE» к 2016 году.
– В том же году компания Uber заявила о том, как она использует SRE.
– В 2017 году компания LinkedIn уже говорила о своей «культуре SRE».
Уже после гигантов остальной рынок онлайн-сервисов обратил внимание на SRE. Высокие ожидания пользователей стали ключевой причиной, но традиционные ИТ-стратегии уже не могли их обеспечить.
Бизнес должен измерять время загрузки в миллисекундах и решать проблемы доступности в течение минут, а не дней, чтобы не отстать от конкурентов. Инструменты и стратегии, которые предлагает SRE, позволяют бизнесу достичь этих целей.
Например, 10 лет назад для развертывания 2000 серверов нужно было 2000 раз выполнить один и тот же длинный список функций по установке операционной системы. Сейчас это происходит в облаке за несколько десятков минут путем вызова всего одной функции.
Как считать и контролировать SRE
Внедрение SRE приносит конкретные бизнес-результаты, помимо непрерывной работы веб-сервисов:
- Снижение рисков при создании обновлений (выбор неверных технологий, ошибки в коде, отсутствие проверок доступа и защиты от основных типов атак (XSS, SQL injection, DOS и др.), неверный выбор интеграций)
- Кратное увеличение скорости разработки
- Сокращение затрат на ФОТ
Чтобы отслеживать, насколько стабильно работает сервис, специалисты SRE выбирают ключевые метрики, собранные в соглашении о целевом уровне обслуживания — Service-Level Objective (SLO).
SLO позволяет всем в компании прийти к общему пониманию требований к надежности, стабильности и доступности. В соответствии с этим закрепляются целевые показатели.
Чтобы их измерить, соглашение содержит конкретные числовые показатели — Service Level Indicator (SLI). Это может быть время ответа, количество ошибок в процентном соотношении, пропускная способность и т.д. — показатели выбираются в зависимости от продукта.
SLO и SLI — это внутренние соглашения, нужные для взаимодействия команды. Обязанности перед клиентами закрепляются в Service Level Agreement (SLA). Это соглашение описывает работоспособность всего сервиса, штрафы за превышение времени простоя или другие нарушения.
Пример SLA:
- сервис доступен 99,95% времени в течение года;
- 99 критических “тикетов” техподдержки будет закрыто в течение трёх часов за квартал;
- 85% запросов в месяц получат ответы в течение 1,5 секунд.
Таким образом, бизнес получает гарантированную непрерывность работы приложений в соответствии с заявленными характеристиками. Если компания может допустить простой сервиса в течение часа в сутки без потерь – в SLA стоит час. Если приложение критичное для бизнеса, и максимальное время простоя – 20 минут в год – специалисты применяют лучшие практики, чтобы добиться этого.
Как внедрять и использовать SRE подход
Специалистов SRE высоко ценят в Google, Apple и Microsoft, в России же эта позиция — пока редкость.
Первым к подходу SRE пришёл финансовый сектор. Для банковских систем непрерывность работы приложений – критична. Потери, которые понесет крупный банк в случае остановки приложения, измеряются в сотнях миллионов.
В Tinkoff, к примеру, вопросом непрерывности занимается 80 SRE-команд — от 4 до 8 человек в каждой. Минимальная сумма заработной платы такого специалиста – 150.000 рублей.
Разберём, что делать компании, чтобы самостоятельно внедрить SRE?
Шаг №1: определиться – нужно ли это компании
Первый вопрос, который следует задать: «Соответствует ли текущий уровень доступности сервиса бизнес-целям?». Для ответа необходимо определить показатели – SLI, SLO – и соотнести ожидания с реальностью.
Если соответствует, то на этом пункте можно остановиться 🙂
Однако, по нашему опыту, в 95% случаев картина “Ожидание – реальность” вынуждает предпринимать срочные действия.
Шаг №2: выбрать инструменты
В SRE много основных инструментов. Некоторые из них следует внедрить в первую очередь, например, мониторинг и инцидент-менеджмент, так как без этого нет понимания, что происходит.
Чтобы выбрать из всего многообразия практик, важно оценивать влияние каждой и внедрять самые результативные. Без этого организация рискует впустую потратить бюджет и время, закупить дополнительный функционал, нанять отдельных специалистов, но так и не обеспечить необходимый уровень непрерывности. Например, один из основных инструментов SRE — это Kubernetes. Нужно ли в таком случае немедленно разворачивать кластер K8s? Если есть понимание, что в текущей ситуации пользы от этого не будет, то лучше разобраться с другими аспектами, а не внедрять Kubernetes.
Нет универсального чек-листа, по которому можно проверить надёжность любого сервиса. Такой чек-лист варьируется от компании к компании. Их объединяет одно: проверка должна проходить на каждом из уровней:
- Проектирование
- Разработка
- Тестирование
- Выкатка
- Документирование
- Мониторинг
- Нагрузочное
- Приемка
- Эксплуатация
“Некоторые думают, что SRE — это что-то странное. Необязательно использовать эту аббревиатуру. Можно просто брать конкретные практики, и шаг за шагом внедрять их. Только нужно знать, что и в какой последовательности применять. Для этого сначала надо понять, что проще и быстрее всего сделать именно для вашей системы” — Владимир Федорков, специалист SRE.
Шаг №3: выбрать стратегию внедрения
Существует 2 варианта:
1. Сразу создавать стратегию внедрения SRE. Собрать аналитику, конкретные цифры, рассчитать стоимость простоя и количество прибыли, которое теряет бизнес. Понять, смогут ли сотрудники справиться с внедрением самостоятельно или потребуется нанимать дополнительных специалистов. Выбрать максимально эффективные практики, подходящие в конкретной ситуации
2. Начать «с низов». Один отдел начинает использовать инструмент, и со временем подход внедряет вся компания, в стремлении получить те же результаты и удобство. Желательно, чтобы у “пилотного” отдела была минимальная загруженность бизнес-задачами, иначе велик риск сбить рабочий график.
Как собрать команду SRE?
По нашим наблюдениям, бизнес начинает с подбора инструментария, затем формирует методологию, и только потом – собирает команду. Как правило, она состоит из сотрудников, которые хорошо понимают продукт и знают его проблемы, но уже занимаются ключевыми вопросами в сервисах компании, а SRE становится для них “приятным бонусом”. Тут критично важна система мотивации и распределения нагрузки.
Site Reliability Engineering — не должность. Это подход и образ мышления. Иногда бизнес понимает это только к середине проекта по модернизации и только там приступает к подбору специалистов.
Важно учитывать: ИТ инфраструктура в рамках SRE подхода строится на стандартах надежности и доступности, над чем работают многие сотрудники компании, поэтому SRE – не только про технологии, но и про коммуникации, а чем раньше новый эксперт освоится и “вольётся” в процессы компании, тем ближе бизнес-результаты внедрения SRE подхода.
Так возникает культура SRE, основные принципы которой:
- Совместное владение — все команды, которые работают над проектом, преследуют одну цель.
- Blame-less культура — при ошибке не ищут виноватых, а вместе разбираются над проблемой.
- Постоянное измерение. Алгоритм принятия решений строится на основе данных, которые регулярно обновляются. Значит, их необходимо считать.
- Инкрементальные изменения. Дробление работы на мелкие итерации и создание стабильных промежуточных результатов.
- Автоматизация. Все, что можно автоматизировать, нужно автоматизировать.
Что делать, если для самостоятельного SRE не хватает времени или ресурсов?
Для тех, кто готов делегировать ответственность и не располагает достаточными ресурсами, существует сервисная модель, она позволяет отдать заботу об ит-инфраструктуре экспертам в SRE. Заказчик получает готовую ценность в виде непрерывно работающего приложения под рамочным контрактом и финансовой ответственностью подрядчика.
Компании, предоставляющие такие ИТ-сервисы, специализируются достаточно узко, знают область глубже и детальнее. В условиях конкуренции на рынке сервис-провайдеры вынуждены быть “идеальным ИТ-отделом” для того, чтобы существовать и работать эффективно.
Конечный продукт – решение для бизнеса при таком варианте подхода – намного выгоднее.
К примеру, в команде поставщика на одного DevOps-специалиста приходится 10 компаний – и он занимается исключительно своими прямыми обязанностями. В компаниях же, в большинстве случаев, на того же специалиста возлагается ряд других задач, не являющихся его профильными. О том, к чему приводит увеличение нагрузки на ИТ-отдел, мы говорили в одном из предыдущих материалов.
Подрядчик предоставляет гарантии, в рамках SLO, SLI и SLA, где описаны конкретные параметры качества услуг, за исполнение которых он несёт финансовую ответственность и обеспечивает бизнес-метрики, которые обозначает заказчик.
Будущее SRE
Два десятилетия назад SRE зародился как узкий подход в крупной компании для решения её высоконагруженных задач.
Мы наблюдаем, как эта практика развивается и с годами становится только популярнее. Даже если темпы её распространения снизятся, подход настолько прочно утвердился в рынке, что трудно представить будущее, в котором SRE нет места.