Бэкапы, которые нельзя зашифровать: как мы пересобрали архитектуру резервного копирования после атаки шифровальщика

Резервное копирование во многих компаниях считается решённой задачей. Но у бэкапов есть одна неприятная особенность: их ценность становится понятна только в момент восстановления.
У ведущего российского дистрибьютора произошёл вполне распространённый и очень болезненный инцидент: в инфраструктуру попал шифровальщик.
На первый взгляд, ситуация должна была быть контролируемой. Бэкапы у компании были. Но в момент восстановления выяснилось, что само наличие резервных копий не позволяет быстро вернуться к привычной работе.
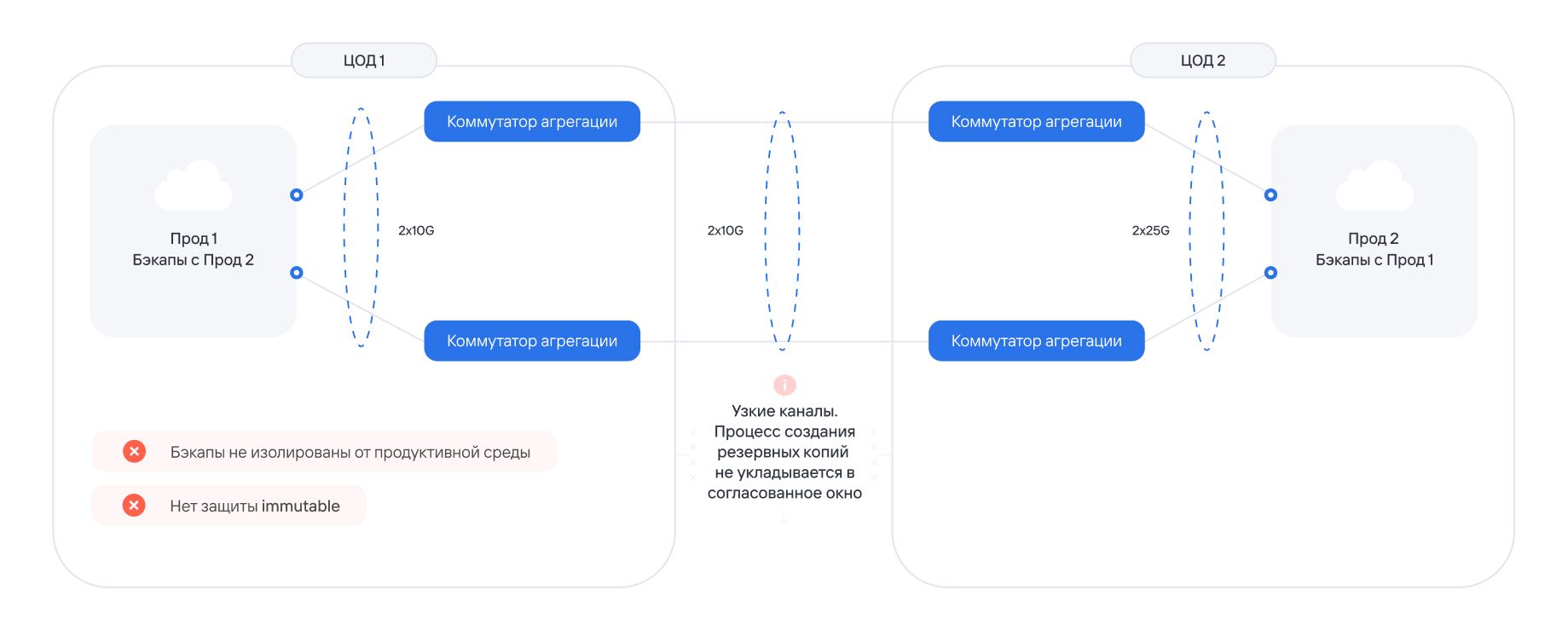
Часть бэкап-инфраструктуры оказалась в той же зоне, что и продуктивные системы и была зашифрована. Восстановление пошло тяжело и заняло значительно больше времени, чем ожидалось. Где-то копии пришлось доставать из других источников, где-то — собирать рабочее состояние постепенно.
В итоге инцидент удалось пережить, но стало понятно: прежнюю архитектуру резервного копирования нужно пересматривать. Рассказываем, почему обычная логика резервного копирования здесь не работала, почему от идеи с NGFW пришлось отказаться, зачем понадобился Hardened Repository и какие выводы из этого кейса полезны для ИТ и бизнеса.
Шаг 1. Выявление настоящей задачи
После инцидента заказчик задумался о новой схеме защиты данных и DR-плане.
Изначально запрос выглядел довольно просто: нужна была отдельная площадка, СХД и возможность вынести туда резервные копии. Логика вполне понятная: если основная инфраструктура уже пострадала, значит, копии нужно увести в сторону.
На старте выглядело как обычная инфраструктурная задача. Подобрать хранилище, организовать связность и разместить бэкапы на другой площадке. Но в процессе обсуждения выяснились нюансы.
Стало понятно, что нужен не классический DR, а нестандартная услуга резервного копирования. Требовалось кастомное инженерное решение на стыке ИТ, бэкап-инфраструктуры и информационной безопасности.
По сути, нужно было спроектировать отдельный защищённый backup-контур, который закрывает несколько вопросов.
- Принять резервные копии на другой площадке и физически разнести их с основной инфраструктурой.
- Сделать так, чтобы уже записанные копии нельзя было изменить или удалить в течение заданного срока — даже если в основной среде снова появится шифровальщик.
- Обеспечить такую транспортную и серверную часть, чтобы схема могла работать с реальными объёмами данных и жёстким окном восстановления.
Иными словами, заказчику нужна была не просто СХД и не DR на всякий случай. Нужна была реализуемая архитектура восстановления: с защищённым репозиторием, высокой пропускной способностью каналов, расчётом производительности и понятной логикой действий после инцидента.
Это важный момент для подобных проектов и в целом для рынка инфраструктурных решений. Клиент может прийти за конкретным элементом — СХД, площадкой, облаком, DR-планом или бэкап-сервисом. Но за этим запросом часто стоит не потребность в отдельной технологии, а более сложная задача: обеспечить восстановление, снизить риски простоя, защитить данные и понять, какая архитектура действительно выдержит реальный инцидент.
При этом решение должно быть не просто надёжным, а соразмерным задаче. Риск можно закрыть очень дорогой схемой: построить избыточный DR, заложить лишние мощности, добавить несколько уровней защиты.
Важно найти баланс между рисками, бюджетом и реальной эксплуатацией, чтобы заказчик не переплачивал за то, что не влияет на результат.
Поэтому работа опытной команды начинается с внимательного разбора задачи. Нужно понять, что именно бизнес хочет получить на выходе, какие ограничения есть по срокам, бюджету, безопасности и эксплуатации, а затем собрать индивидуальное решение и связать технологии в систему, которая решает конкретную проблему
Шаг 2. Перевод RPO и RTO в инженерный расчёт
У заказчика было условие: RTO — 8 часов. За это время нужно было вернуть в работу критичную инфраструктуру после инцидента.
Для ИТ это сразу превращается в инженерный расчёт: выдержит ли вся цепочка восстановления нужную скорость — от чтения данных из репозитория до записи на продуктивную СХД и запуска сервисов.
И здесь нельзя считать по простой формуле: взяли объём данных, поделили на скорость интерфейса и получили теоретическую цифру. На практике важны не только каналы. Нужно учитывать скорость чтения из Hardened Repository, передачу данных между площадками, производительность дисковой подсистемы, FC-связность, запись на целевое хранилище и возможные узкие места при восстановлении систем.
Если хотя бы один участок этой цепочки не выдерживает нужный темп, RTO на бумаге начинает расходиться с реальным временем восстановления.
В этом проекте объём данных составлял около 200 ТБ, а суточный инкремент 25 ТБ. Поэтому задача быстро перешла в формат полноценного инженерного расчёта.
Для регулярного резервного копирования проверяли:
- пропускную способность каналов под суточный инкремент и полный бэкап;
- производительность backup-прокси;
- нагрузку на сервер репозитория;
- скорость записи на СХД;
- влияние бэкап-трафика на продуктивную инфраструктуру.
Для восстановления, где критичным был RTO 8 часов, считали другую цепочку:
- чтение из Hardened Repository;
- передачу данных в сторону продуктивной площадки;
- производительность дисковой подсистемы на чтение;
- FC-связность;
- запись на продуктивную СХД;
- запуск систем после восстановления данных.
По расчётам стало понятно, что для объёма около 200 ТБ и RTO 8 часов транспортная часть становится одним из ключевых элементов архитектуры восстановления.
В проекте фигурировала потребность порядка 85 Гбит/с устойчивой скорости передачи с учётом накладных расходов и реальной работы инфраструктуры. Поэтому межплощадочная связность здесь была частью сценария восстановления.
Шаг 3. Поиск оптимального решения
После расчетов команда начала проверять возможные технические подходы.
Первой гипотезой был DR.
Вполне логичный и первый вариант, который рассматривают для высоконагруженной системы. Если основная площадка может пострадать, значит, нужно подготовить резервную инфраструктуру и восстанавливаться уже там.
Но полноценный DR для этой задачи оказался слишком тяжёлым. Он требует фактически второй инфраструктуры, готовой принять нагрузку при отказе основной. Для объёмов заказчика это резко увеличивало бюджет и усложняло эксплуатацию.
При этом DR не гарантировал восстановление. Если резервные копии не защищены от изменения и удаления, они всё равно остаются уязвимыми — даже за пределами основной инфраструктуры.
Проверили идею с NGFW.
После атаки заказчик хотел добавить между основной инфраструктурой и бэкап-контуром отдельный защитный барьер.
Логика понятная: если источник риска находится в продуктивной среде, значит, трафик из этой среды в сторону репозитория нужно дополнительно контролировать.
В качестве такого барьера рассматривался NGFW — межсетевой экран нового поколения, который должен был проверять backup-трафик на лету.
Но на практике этот вариант также оказался нерабочим. Трафик между бэкап-сервером и репозиторием — это служебный поток, необходимый для работы резервного копирования. Нужные протоколы и порты всё равно пришлось бы разрешить. Кроме того, проверка таких объёмов данных на высоких скоростях резко увеличивала стоимость и сама могла стать узким местом.
А главный вопрос всё равно оставался открытым: как защитить уже записанные бэкап-копии от изменения или удаления. В итоге стало понятно, что нужна архитектура, которая защищает сами резервные копии, учитывает жёсткое окно восстановления и не раздувает проект до избыточной по бюджету схемы.
Шаг 4. Выбор Hardened Repository
После уточнения задачи и проверки гипотез команда пришла к решению строить бэкап-контур на базе Hardened Repository.
Hardened Repository — репозиторий для резервных копий, который настраивается так, чтобы уже записанные backup-файлы оставались неизменяемыми в течение заданного срока. Для бэкап-системы он выглядит как место хранения копий, но внутри работает важный механизм защиты: файл можно записать, но нельзя удалить, перезаписать или изменить до окончания периода immutability.
Такой подход подошел по нескольким причинам.
- Он закрывал главный риск после атаки шифровальщика: резервные копии не должны быть уничтожены или испорчены вместе с основной инфраструктурой.
- Этот подход защищал именно то, что должно остаться последней точкой восстановления, — сами бэкап-копии. После записи в Hardened Repository они становятся неизменяемыми на заданный срок: их нельзя удалить, перезаписать или испортить штатными средствами.
- Это решение лучше соответствовало бюджету и задаче, чем полноценный DR. Заказчику не нужно было строить вторую параллельную инфраструктуру там, где ключевая цель — сохранить рабочую точку восстановления и иметь возможность подняться из неё в заданное окно.
Но у Hardened Repository есть и обратная сторона. Если для копий задан срок неизменяемости, их нельзя удалить раньше времени. Даже тогда, когда место на хранилище заканчиваться. Это и есть смысл защиты: бэкап-файлы нельзя изменить или стереть до окончания заданного периода.
В эксплуатации это накладывает жёсткие требования к расчёту ёмкости.
Поэтому на этапе проектирования нужно было заранее учитывать:
- общий объём данных;
- суточный прирост;
- срок хранения неизменяемых копий;
- запас по ёмкости;
- скорость записи новых бэкапов;
- возможность расширения хранилища.
Иначе можно получить неприятный парадокс: копии защищены, но новые бэкапы некуда записывать, потому что старые ещё нельзя удалить.
Этот риск закрыли расчётом ёмкости и производительности СХД, а также возможностью масштабировать хранилище при росте объёмов. То есть immutability рассматривали как часть общей архитектуры: она защищает копии, но требует заранее рассчитанного места, запаса и понятной политики хранения.
Шаг 5. Проработка схемы внедрения
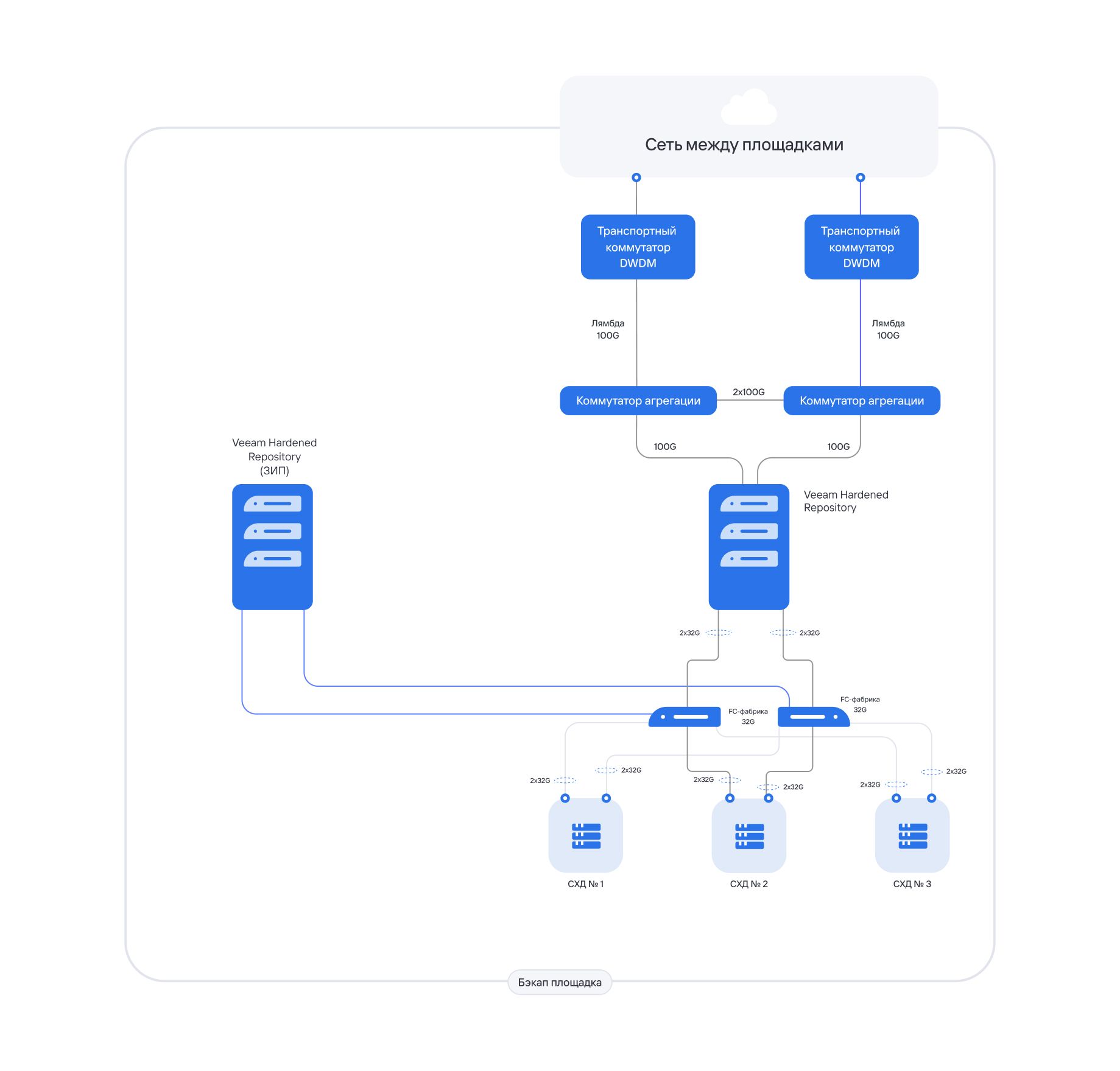
Собрали полную цепочку: от продуктивной инфраструктуры заказчика до защищённого репозитория на другой площадке — для резервного копирования — и обратно — для восстановления.
В целевой схеме бэкап-контур вынесли на отдельную площадку, развернули Hardened Repository и связали его с СХД, на которых должны храниться резервные копии. Со стороны заказчика бэкап-система получает доступ к репозиторию только по тем протоколам и портам и только для тех учетных записей, которые нужны для работы резервного копирования.
Проработали транспортную часть.
Для заданного окна восстановления нужны были каналы с высокой пропускной способностью: при объёме около 200 ТБ данные должны были успевать передаваться между площадками в расчётное время. Поэтому межплощадочную связность сразу проектировали как часть сценария восстановления, а не как отдельный инфраструктурный слой.
Также пришлось учитывать производительность всей цепочки восстановления. Канал сам по себе не гарантирует возврат сервисов за 8 часов. Для RTO критично, насколько быстро инфраструктура сможет прочитать данные из Hardened Repository, передать их обратно на площадку заказчика, записать на продуктивную СХД и поднять необходимые системы.
Отдельно считалась рабочая нагрузка самого backup-контура: как быстро данные записываются в репозиторий, выдерживает ли СХД поток заданий, справляются ли backup-прокси и не создаёт ли регулярное копирование лишнюю нагрузку на продуктив.
Отдельный блок работ касался безопасности.
Доступ к репозиторию ограничили: разрешили только необходимые соединения, исключили лишние административные доступы, добавили двухфакторную аутентификацию и защиту от перебора учётных данных. Логика была простая: если основная среда снова окажется скомпрометирована, атакующий не должен получить прямой путь к бэкап-копиям.
Для надежности схемы предусмотрели запасной сервер с заранее подготовленной конфигурацией. Это не полноценный active-standby-кластер, но практичный вариант резервирования: если основной элемент выходит из строя, инфраструктуру можно быстрее переключить на подготовленный запасной узел.
В результате получилась не просто схема хранения бэкапов, а рабочая архитектура восстановления. Копии уходят на отдельную площадку, записываются в Hardened Repository, становятся неизменяемыми на заданный срок и остаются доступными для восстановления через рассчитанную транспортную и серверную инфраструктуру.
Техническое условие проекта: около 200 ТБ данных и RTO до 8 часов. Поэтому отдельно считались цепочка резервного копирования и цепочка восстановления: запись в репозиторий, нагрузка на СХД и бэкап-серверы, чтение из Hardened Repository, передача данных обратно, запись на продуктивную СХД и подъём систем.
Что показал этот кейс
Бэкапы сами по себе не гарантируют восстановление.
Это справедливо для любой компании: можно регулярно создавать копии, получать успешные отчёты и всё равно столкнуться с проблемой в момент инцидента. Восстановление зависит не только от того, есть ли копии. Важны архитектура, доступы, каналы, хранилище, скорость чтения и записи, политики хранения и готовность команды действовать по понятному сценарию.
Поэтому стратегия восстановления не должна строиться вокруг одной технологии. Где-то действительно нужен Hardened Repository. Где-то — полноценный DR. Где-то — пересмотр бэкап-политик, усиление связности между площадками или изменение модели хранения.
Решение всегда зависит от задачи: какие риски нужно закрыть, сколько данных нужно восстановить, какое окно простоя допустимо и какой бюджет разумен для бизнеса. Важно сначала честно разобраться и понять, что именно нужно защищать и от какого сценария. А уже потом выбирать технологию, оборудование и архитектуру.
Мы помогаем пройти этот путь: разобрать текущую схему резервного копирования, отделить реальные задачи от первоначальных гипотез, перевести RPO/RTO в инженерные параметры и собрать индивидуальное решение под инфраструктуру, риски и бюджет заказчика.
Если вы хотите понять, выдержит ли ваша бэкап-архитектура реальный инцидент, задайте вопрос нашим инженерам. Мы посмотрим на вашу задачу, поможем найти слабые места и предложим вариант решения без лишней сложности и переплаты. Заполните короткую форму обсудим, как должна выглядеть ваша стратегия восстановления.