Иллюзия безопасности: почему бэкапы не спасают бизнес

Практика последних лет в России показывает: наиболее разрушительные простои вызывают не только пожары и поломки железа, но и непредсказуемые сценарии, при которых рядовой ИТ-сбой перерастает в катастрофу.
У компаний есть инфраструктура, план аварийного восстановления, где-то в документах прописаны время восстановления (RTO) и количество данных, которые готовы потерять (RPO). Но как только случается реальный сбой, бумажные стратегии рушатся.
Более того, злоумышленники давно поняли эту слабость и теперь целенаправленно уничтожают резервные копии.
В статье посчитаем, во сколько сбои на самом деле обходятся бизнесу, вспомним самые громкие инциденты за последние пять лет и дадим практические рекомендации по спасению данных.
Что говорит статистика
Есть два типа инцидентов, способных обнулить ИТ-инфраструктуру. На них стоит обратить особое внимание.
- Инфраструктурные аварии. Uptime Institute показывает, что более половины респондентов сообщали об аварии за три года. Простой обходится дорого: 54% респондентов оценили потери от последней значимой аварии выше $100k, а 16% — свыше $1 млн.
- ИБ-инциденты, шифровальщики. По результатам опроса 5 000 организаций, 59% столкнулись с шифровальщиком за последний год. Средняя стоимость восстановления инфраструктуры составила $2,73 млн, а 56% пострадавших признали, что помимо этого платили выкуп, чтобы вернуть данные.
Но самая пугающая статистика в другом. В 98% атак злоумышленники пытались скомпрометировать бэкапы, и в 79% попытки были успешными. Хакеры понимают, что бизнес не заплатит, если сможет быстро восстановиться из резервной копии.
Рассмотрим конкретные примеры громких инцидентов в мире
| Кейc | Тип аварии | Влияние на бизнес | Потери |
| Universal Health Services, 2020 | шифровальщик | отключение ИТ‑приложений, работа «на бумаге», задержки биллинга | оценка неблагоприятного эффекта ~$67 млн |
| OVHcloud, 2021 | пожар в ЦОДе | массовые простои клиентов, часть данных потеряна | 3,6 млн сайтов офлайн (464 тыс доменов); финансовые потери — десятки млн € |
| Colonial Pipeline, 2021 | шифровальщик | остановка критической инфраструктуры | простой 7 суток; выкуп $4,4 млн, часть средств изъята |
| British Library, 2023–2025 | шифровальщик | пересборка инфраструктуры, полу-оффлайн | похищено ~600 ГБ; утечка затронула ~456 тыс пользователей; восстановление продолжалось и в 2025 |
| CrowdStrike, 2024 | сбой обновления | массовые падения Windows, остановка процессов | затронуто 8,5 млн Windows‑устройств; Delta Air Lines оценила потери в $380 млн + $170 млн |
| UnitedHealth Group и Change Healthcare, 2024–2025 | шифровальщик | остановка работы с медицинскими счетами по стране | через систему проходит ~50% медицинских счетов США; эффект до $1,6 млрд за 2024; утечка затронула 192,7 млн человек |
Потери на миллионы долларов случаются не только у глобальных игроков, но и у российских компаний. Разберем ТОП-8 громких инцидентов в России за последние несколько лет.
Аварии, которые ломали RPO и RTO в России
1. «Гедеон Рихтер» — масштабная остановка поставки лекарств в РФ из-за технических сбоев в системе маркировки, осень 2020.
Проблемы продолжались минимум несколько недель, с конца сентября по 22 октября. Сбой парализовал контур маркировки и связанные с ним критичные бизнес‑процессы ввода и реализации препаратов.
2. Кибератака на Rutube, май 2022.
Сервис называл атаку «самой мощной». Злоумышленникам удалось поразить более 75% основной инфраструктуры и, что самое страшное, 90% резервных копий. Длительность простоя составила более суток.
3. Атака шифровальщиком на СДЭК, май 2024 года
Сбой коснулся всех систем: сайта, мобильного приложения, личных кабинетов и работы ПВЗ. Добрались и до бэкапов. Эксперты оценивают ущерб от простоя примерно в 300 млн–1 млрд рублей.
Восстановление заняло более трёх дней. Важный урок: бизнес‑последствия не исчезают в тот момент, «когда сайт снова открылся»: хвост из очередей, ручной обработки заказов, просрочек SLA, претензий и потери доверия тянется месяцами.
4. Кибератака на онлайн‑сервисы ВГТРК, октябрь 2024
ВГТРК публично говорила о «беспрецедентной атаке», в результате которой обрушилось онлайн‑вещание и внутренние сервисы.СМИ утверждали, что хакеры «стерли всё… включая резервные копии».
5. Сбой облачных сервисов из‑за проблем энергообеспечения ДЦ Яндекса, март 2025
Роскомнадзор объяснил проблему сбоем энергообеспечения одного из дата‑центров. Простой продлился ~95 минут и затронул зону доступности облака и зависящие от него сервисы.
6. Атака шифровальщиком на ЛУКОЙЛ, март 2025
Атаке затронула два крупных подразделения, сообщалось о парализованной работе офисов и проблемах с безналичной оплатой на АЗС. Восстановление заняло примерно сутки.
7. Атаки на аптеки «Столички» и «Неофарм», июль 2025
В результате сбоя в течение суток были закрыты часть офлайн-точек, а онлайн‑сервисы полностью упали. По оценке СМИ, средняя дневная выручка сетей ~305 млн ₽, то есть каждый час простоя стоил бизнесу колоссальных денег.
RTO в ритейле — это восстановить кассы, учёт, системы лояльности и вернуться к нормальному обслуживанию. Если контур резервирования не отлажен, восстановление подобных крупных инфраструктур может занимать недели.
8. Кибератака на ВСК, ноябрь 2025
Инцидент затронул работоспособность ИТ‑инфраструктуры, наблюдались проблемы в работе сайта и приложения. Длительность простоя составила порядка недели до полного восстановления сервисов — критичный срок для финансового сектора.
Как посчитать реальные RPO и RTO
Если вы не считаете стоимость простоя, вы не можете принимать рациональные решения о внедрении ИТ-инструментов. Без этой цифры компания либо переплачивает за избыточную инфраструктуру, либо фатально недооценивает риски.
RPO (Recovery Point Objective) — это сколько данных вы готовы потерять за определённый промежуток времени. Проще говоря, за какой период вы готовы безвозвратно потерять информацию (например, все транзакции за последние 4 часа до аварии)?
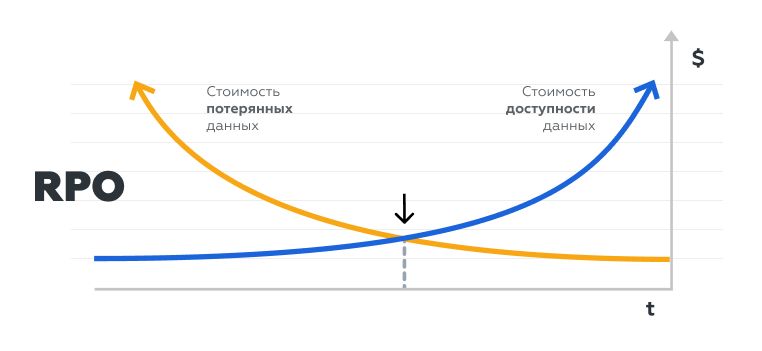
RTO (Recovery Time Objective) — это сколько времени бизнес готов быть без сервиса без критичных потерь в деньгах.
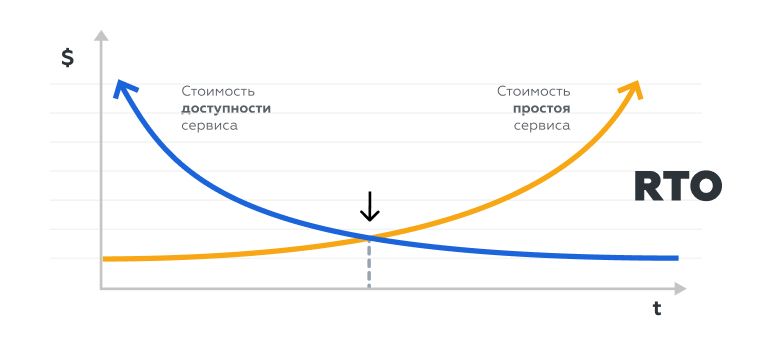
После подсчёта RPO и RTO появляется честная развилка:
- либо вы инвестируете в архитектуру под заданные RTO и RPO, создаёте и тестируете план восстановления под разные сценарии — от сбоя кондиционера в ЦОДе до атаки шифровальщика;
- либо сознательно выбираете риск и закладываете «страховой фонд» под аварии — что обычно дороже, потому что цена инцидента нелинейна.
Практические рекомендации для бизнеса и ИТ
Данные по рынку показывают, что инциденты на миллионы — это не редкость. И итоговая стоимость ущерба зачастую определяется не «техникой», а именно параличом бизнеса и длительностью простоя.
Для топ-менеджмента (бизнеса)
Первое, что стоит сделать совместно с CTO:
- оцифровать стоимость часа простоя по основным бизнес‑процессам (пусть даже диапазоном), опираясь на реальные финансовые факты компании;
- смоделировать «худший сценарий»: что именно должно продолжать работать при любых условиях и в каком качестве;
- утвердить приоритеты: какие сервисы должны восстановиться первыми и за какое время.
Для CIO и CTO:
- проверить, что RTO/RPO «сшиты» с реальными возможностями записи, чтения и каналов связи;
- заложить сценарии, где ломается не только ваш ЦОД, но и подрядчик, вендор;
- перевести DR (Disaster Recovery) из «документа для галочки» в регулярную практику: проводить тесты восстановления не реже, чем меняется инфраструктура и критичные приложения.
Для ИТ‑команд:
- сделать инвентаризацию: где реально лежат бэкапы, в каких доменах доверия, какая у них неизменяемость, кто может их удалить и зашифровать;
- пройти путь восстановления «вслепую»: смоделировать ситуацию, когда мониторинг, AD (Active Directory), почта недоступны, и нужно поднимать инфраструктуру;
- понять, во что вы будете упираться: в сеть, в ручной труд, в слетевшие лицензии, в совместимость версий, в ключи шифрования илив доступ к облачным аккаунтам.
Итоги простые. Кейсы последних лет показывают: «формальные» RPO и RTO без инженерной проверки расходятся с реальностью ровно тогда, когда это стоит дороже всего. Любая случайность — пожар в ЦОДе, шифровальщик и сбой обновления — могут стоить миллиарды.
Мы готовы ответить на ваши вопросы по стратегиям реального восстановления и помочь выстроить пуленепробиваемую архитектуру резервного копирования. Заполните короткую форму — мы свяжемся с вами, обсудим вашу текущую инфраструктуру и проконсультируем по надежной защите данных.