Аварийное восстановление: всё о Disaster Recovery за 15 минут
Согласно исследованию Uptime Institute, 44% организаций сталкивались с аварийными ситуациями, которые повлияли на бизнес.
Помимо аварий и поломок оборудования, ИТ инфраструктуре угрожают:
– природные катастрофы;
– политические конфликты;
– срыв поставок;
– сбои в каналах связи;
– одностороннее расторжение договорённостей;
– санкции;
– кибератаки;
и многое другое.
Для обеспечения отказоустойчивости, непрерывности работы и сокращения рисков потери данных, используют Disaster Recovery(DR), или аварийное восстановление — инструмент для восстановления ИТ инфраструктуры, данных и приложений.
Этапы аварийного восстановления
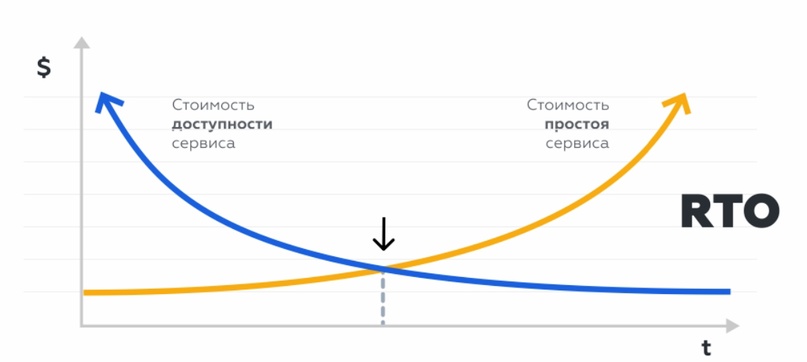
1 этап – выбор бизнес-критичных систем, комплексов, которые будут подвергаться защите с помощью DR. Определение RTO(Recovery Time Objective) и RPO(Recovery Point Objective).
2 этап – анализ ИТ-инфраструктуры предприятия. Разработка стратегии DR. Выбор технических решений.
3 этап – внедрение решений и формирование документации.
4 этап – тестирование, корректировка.
1 этап – выбор бизнес-критичных систем, комплексов, которые будут подвергаться защите с помощью DR. Определение RTO и RPO.
Бизнес требует от ИТ департамента непрерывной работы критичных приложений и недопущения потерь данных.
Хорошо, если и бизнес и ИТ команда понимают друг друга и воспринимают непрерывность равнозначно. Восстановленная виртуальная машина или “поднятый с колен” сервер совсем не равны работающему приложению или целому бизнес-процессу.
Поэтому начинают с вопроса – а какие системы и приложения вообще являются бизнес-критичными?
Для некоторых предприятий это 1С, для других – веб-приложение с интернет-магазином, а для третьих – биллинговая система. Для каждого приложения определяем допустимый уровень доступности. Для этого используем метод BIA (Business Impact Analysis).
Он находит взаимосвязи между процессами, внутренними и внешними сторонами, цепочками поставок, активами, персоналом, технологиями, и т.д. По результатам BIA бизнес получает требования к непрерывности работы бизнес-процессов. При этом, стоимость решения не должна превышать ущерб от потерь. Для этого определяем показатели RTO и RPO.
RTO (Recovery Time Objective) – это промежуток времени, в течение которого система может оставаться недоступной в случае аварии.
RTO помогает оценить, какой урон будет нанесён бизнесу, если система будет стоять час, сутки, неделю и, исходя из этого, понять, какое время является приемлемым, а какое – нет. Выбираем наиболее высоконагруженный период (например, чёрная пятница, новогодняя распродажа и т.д.), считаем потери за промежуток времени и определяем RTO. Если он равен 2 часам, значит, система должна возобновить работу за 2 часа.
RPO (Recovery Point Objective) – это максимальный период времени, за который могут быть потеряны данные. На точке пересечения графиков стоимости потерь и доступности получаем время восстановления и лучшую стоимость.
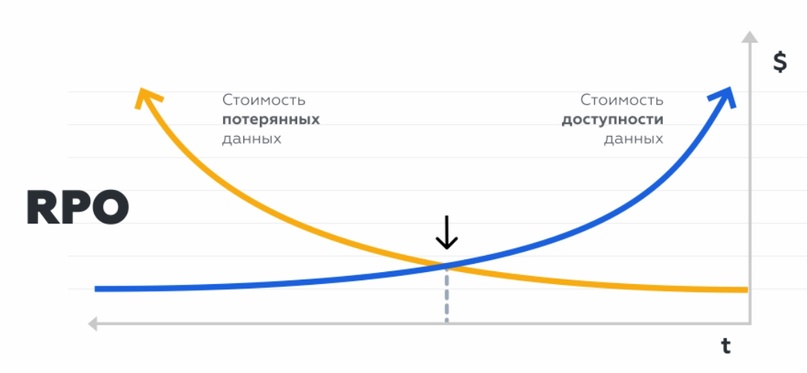
RPO определяет частоту резервного копирования.
— Если он равен суткам – будем записывать бэкап с периодичностью раз в 24 часа.
— Если максимальное время, за которое бизнес может потерять данные – 5 минут, то разрабатываем дополнительную стратегию обеспечения сохранности данных – например, подключаем инструменты репликации, кластеризации и т.д.
Универсальных значений показателей RTO и RPO не существует. В случае небольшого обувного магазина простой в сутки не даст ощутимых потерь, но совершенно другая история – операционная деятельность банков.
2 этап – анализ ИТ-инфраструктуры предприятия. Разработка стратегии DR. Выбор технических решений.
Выясняем, может ли ИТ-инфраструктура обеспечить нужный уровень RTO. Для этого:
– Соотносим все компоненты с ИТ-системами, участвующими в организации непрерывной работы;
– Проверяем архитектуру резервирования;
– Выявляем специфические особенности ИТ-ландшафта организации.
Определение бизнес-критичных систем, оценка потерь в случае аварии и результаты аудита существующей ИТ-инфраструктуры помогают договориться бизнесу и ИТ-отделу и определиться, какой уровень DR подойдет под конкретный бизнес-процесс и бюджет.
Варианты:
– в рамках одного ЦОДа между разными серверами;
– между ЦОДами;
– между “землёй” и облаком;
– между облаками.
2 наиболее популярных схемы:
1. Бэкапы и быстрое восстановление из облака (DRaaS Backup & Restore).
Относительно бюджетный вариант, поскольку нет затрат на дублирующую инфраструктуру. Бизнес платит за объём данных в облаке и временное использование виртуальных машин в случае аварии. RPO и RTO в данном случае составляют несколько часов.
Порядок действий:
Делаем бэкап в облако. В случае наступления локальной аварии, приложения переключаются на виртуальные машины, которые берут на себя нагрузку. В это время восстанавливаем инфраструктуру, возобновляем работу и делаем новые бэкапы.
2. Параллельная инфраструктура
Метод кратно дороже, чем первый, время аварийного восстановления занимает от двух-трёх секунд до нескольких минут. Механизм работы подробно описали в материале о синхронной и асинхронной репликации.
Стоимость выбранного решения сравниваем с ущербом от простоя и корректируем показатели.
3 этап – внедрение решений и формирование документации.
Как правило, в комплект входит 4 документа:
1. SLA (Service-Level Agreement) – это договор между поставщиком и клиентом, в котором закрепляем:
– требования бизнеса;
– перечень и объём услуг;
– обязанности;
– ожидания сторон;
– ключевые показатели эффективности.
Метрики SLA (цифры, которым должен соответствовать бизнес-процесс)
Благодаря SLA бизнес получает гарантированную доступность сервисов в соответствии с заявленными характеристиками.
2. Результаты аудита ИТ-инфраструктуры и проект новой архитектуры. Описание методов и технологий в стратегии DR. Данный документ можно назвать чек-листом для построения отказоустойчивой ИТ-инфраструктуры.
2.1. План резервирования и резервного копирования. Определяет способы, время восстановления по каждому элементу, а также частоту и глубину бэкапов.
3. RunBook (книга запуска) — пошаговая инструкция по восстановлению. Документ, в котором фиксируют последовательность действий для каждого участника ответственной команды в момент аварии.
4. DRP (Disaster Recovery Plan) – подробный план аварийного восстановления. Отвечает на вопрос: что делать в момент аварии?
– Описывает порядок действий – что делаем на каждом конкретном этапе;
– Регламентирует зоны ответственности;
Например, ответственность за закупку оборудования, согласно DRP, лежит на директоре департамента информационных технологий. Если нужно приобрести новый сервер, сотрудник обращается к нему.
– Закрепляет состав команд по аварийному восстановлению
В DRP распределяем обязанности – по людям, по группам, по их взаимодействию в различных вариантах развития событий.
Например, для штатного случая способ связи между командой – стационарный телефон. На случай отключения электроэнергии в DRP прописываем альтернативный вариант связи.
Все подобные организационные нюансы учитываются в плане аварийного восстановления.
4 этап – проведение тестирования, корректировка
Чтобы убедиться, что реальные показатели не отличаются от требуемых и довести действия команды до автоматизма, проводим репетиции аварийных ситуаций и восстановлений.
Аварийные работы по восстановлению проводим отдельно для каждого риска, например DR-команда:
– Отключает сетевой кабель и тестирует падение интернет-провайдера.
– Оценивает влияние человеческого фактора, когда системный администратор не выходит на связь.
– Имитирует кибератаки и вмешательства.
Важно учесть, что единоразового тестирования режима аварийного восстановления недостаточно. Ответственная группа должна регулярно проводить учения (например, раз в 6 месяцев) и поддерживать актуальное состояние DRP.
Все недочёты и допущенные ошибки фиксируем в план и совершенствуем его до тех пор, пока реальное время восстановления не будет совпадать с запланированным.
Зачем нужен план аварийного восстановления (DRP)? Почему бэкапов недостаточно?
Резервное копирование данных — обязательная часть Disaster Recovery, но это лишь часть. Даже методика “3-2-1” не сможет обеспечить быстрое восстановление и защитить от риска потери критически важных данных.
Если проводить аналогию, то бэкап – это подушки безопасности в автомобиле. В случае аварии, до того, как они сработают, есть ещё несколько линий обороны – ремни безопасности, система тормозов, реакция водителя, специальный вывод из строя некоторых систем.
Резервное копирование – последний рубеж. А DRP предусматривает, какие системы и в каком порядке будут срабатывать перед восстановлением из бэкапов.